📢 Accepted at IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2026
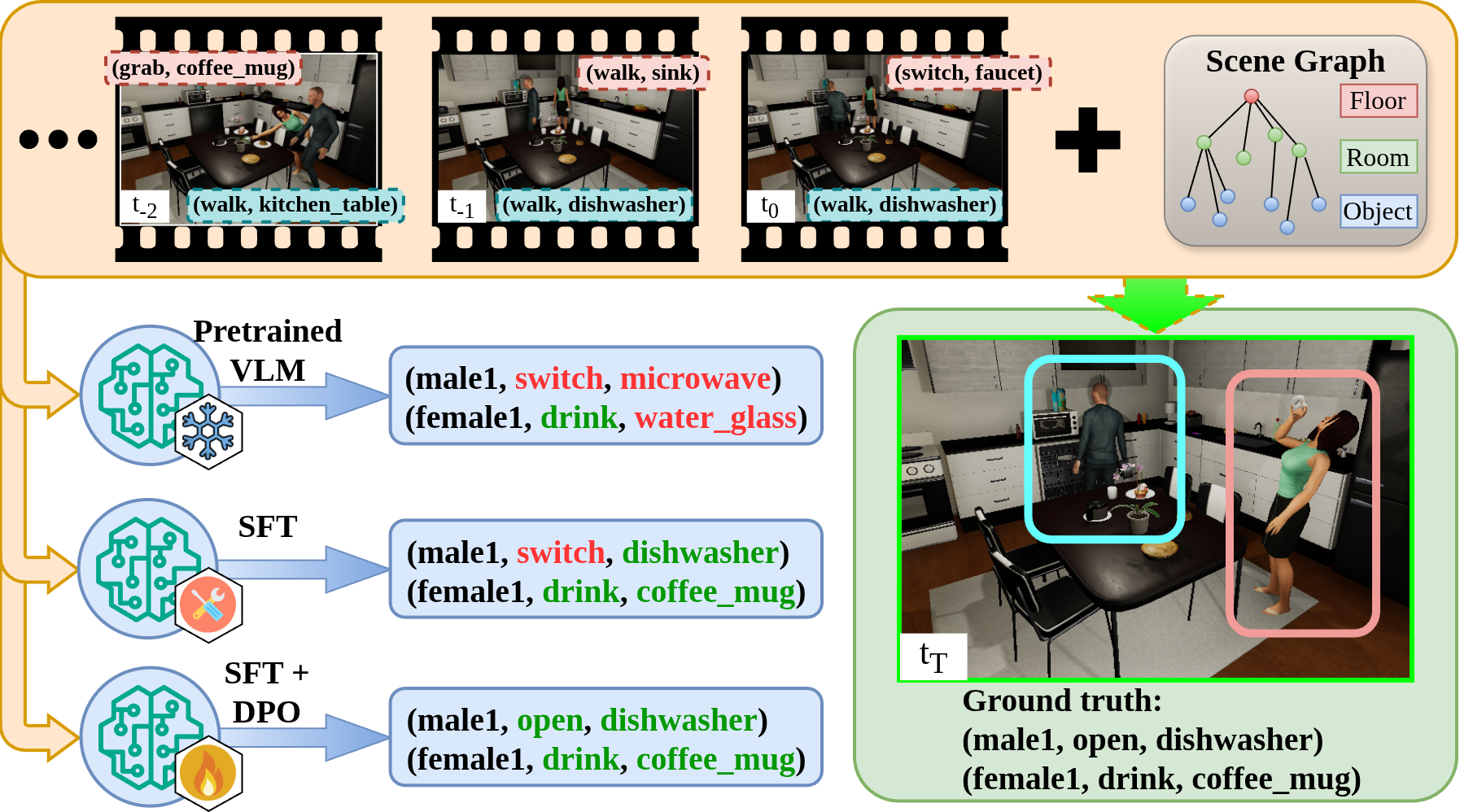
Accurately predicting human behaviors is crucial for mobile robots operating in human-populated environments. While prior research primarily focuses on predicting actions in single-human scenarios from an egocentric view, several robotic applications require understanding multiple human behaviors from a third-person perspective. To this end, we present CAMP-VLM (Context-Aware Multi-human Prediction): a Vision Language Model (VLM)-based framework that incorporates contextual features from visual input and spatial awareness from scene graphs to enhance prediction of humans-scene interactions. Due to the lack of suitable datasets for multi-human behavior prediction from an observer view, we perform fine-tuning of CAMP-VLM with synthetic human behavior data generated by a photorealistic simulator, and evaluate the resulting models on both synthetic and real-world sequences to assess their generalization capabilities. Leveraging Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO), CAMP-VLM outperforms the best-performing baseline by up to 66.9% in prediction accuracy.
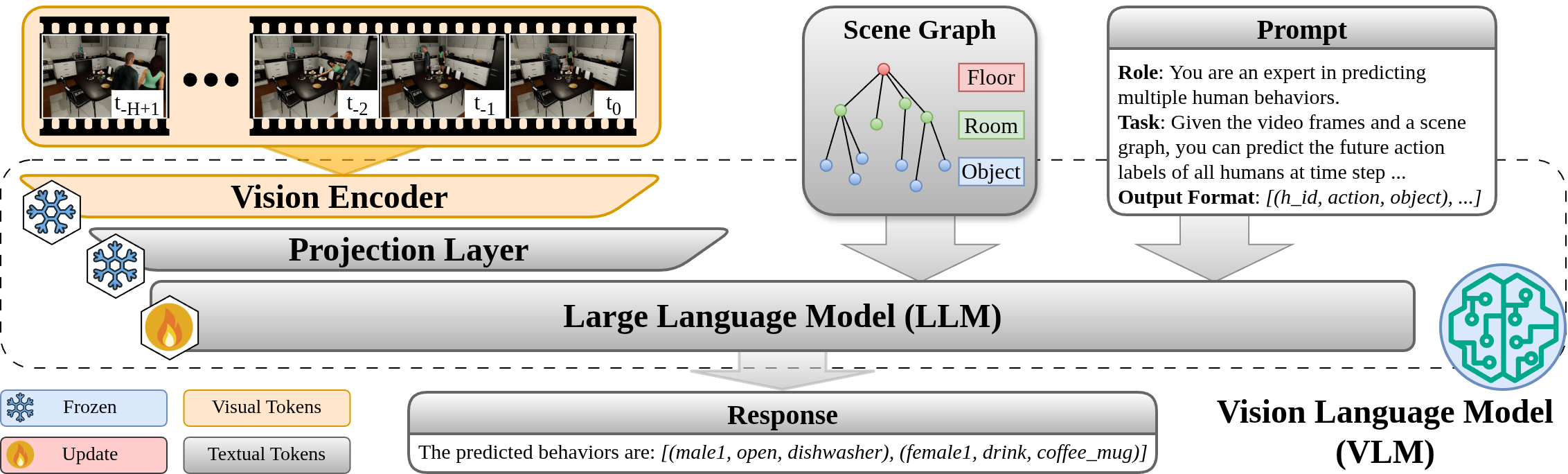
An overview of CAMP-VLM, a VLM-centered framework for Context-Aware
Multi-human Prediction. The video frames are processed by the vision encoder
into visual tokens, which are then passed into the Large Language Model (LLM) backbone via the projection
layer. The context encoded in the images helps the VLM to discern interactions between humans and the scene.
The scene knowledge encoded in the Scene Graph (SG) is provided to ground the predictions in the provided
scene topologies and relationships. Under the guidance of the user-provided prompt, the LLM predicts human
behaviors in the given format. The LLM is fine-tuned to improve the prediction performance, while the weights
of the vision encoder and projection layer remain unchanged.
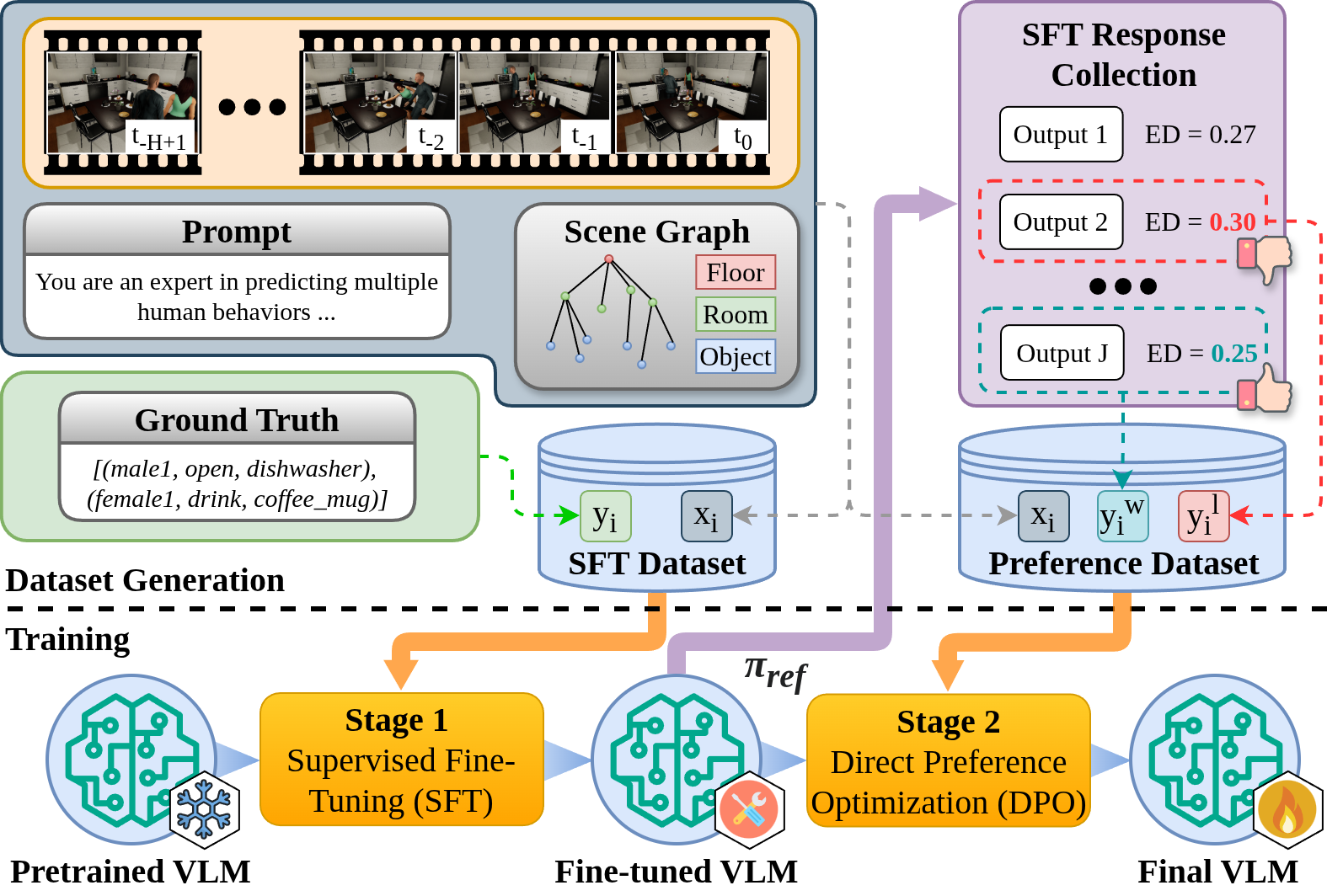
We introduce a two-stage fine-tuning process combining Supervised Fine-Tuning (SFT) and Direct Preference
Optimization (DPO) to improve the prediction performance of pre-trained VLMs.
Stage 1 (SFT): A dataset consisting of ground truth input-output pairs (xi, yi) is to be prepared for the SFT process, as shown in the top-left part of the figure above. Each input xi comprises a sequence of video frames, a scene graph, and a prediction prompt as described previously, while the output yi refers to the ground truth behavior labels. In this work, we employ Low-Rank Adaptation (LoRA) to the open-source pre-trained VLMs.
Stage 2 (DPO): While SFT provides strong task grounding, its gains are limited by dataset
size. Although DPO is often used for human preference alignment, here it is used to bias the VLM toward
predictions with smaller character-level deviations, improving performance without enlarging the dataset.
For DPO, a preference dataset is necessary. While the inputs xi remain the same as
in the SFT dataset, DPO requires additional chosen and rejected predicted labels,
yiw
and yil, as shown in the top-right part of the figure above.
To collect preference data, the fine-tuned reference model from the last stage is inferred to generate a batch
of outputs and construct an SFT response collection. Using a pre-defined similarity metric such as Edit
Distance (ED), a preferred and a non-preferred response are selected according to the lowest and highest ED
values, respectively.
The model is then trained by minimizing a loss function derived from the KL-constrained reward maximization
objective used in RLHF but reformulated to directly optimize the policy.
The prompt is formulated as follows:


Example scenes of the datasets. From left to right: kitchen, living room, bedroom from VirtualHome simulation, and office kitchen and living room in the real-world video recordings.
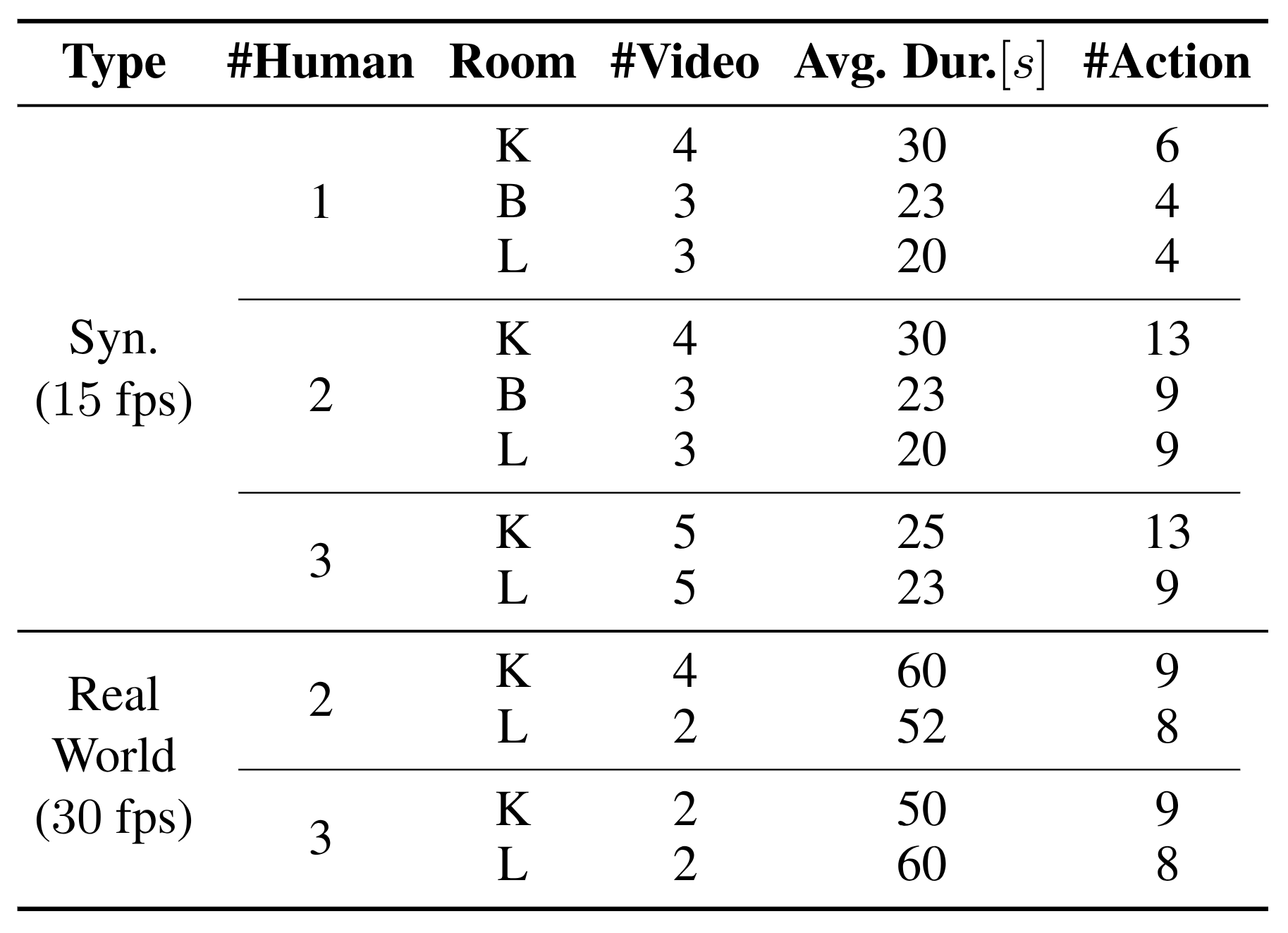
Statistics of the datasets. The rooms cover K(itchen), B(bedroom), and L(iving room). Duration and the number of Actions per human are averaged through all videos.
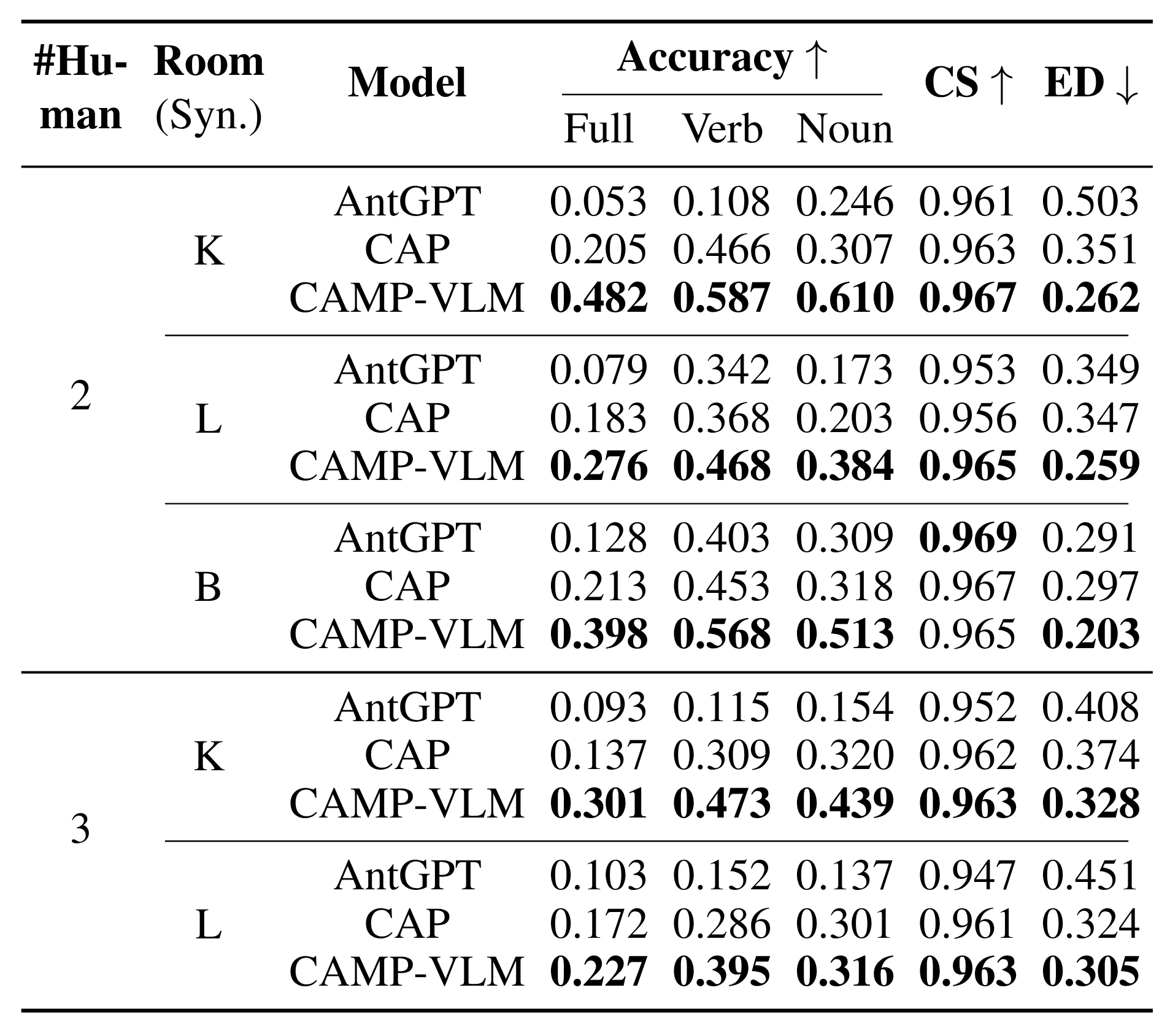
Results of all models in multi-human scenarios across all synthetic K(itchen), B(bedroom), and L(iving room) scenes. Higher values of accuracy and Cosine Similarity (CS) and lower values of Edit Distance (ED) indicate better performance. Bold numbers are the best results in each sub-category.
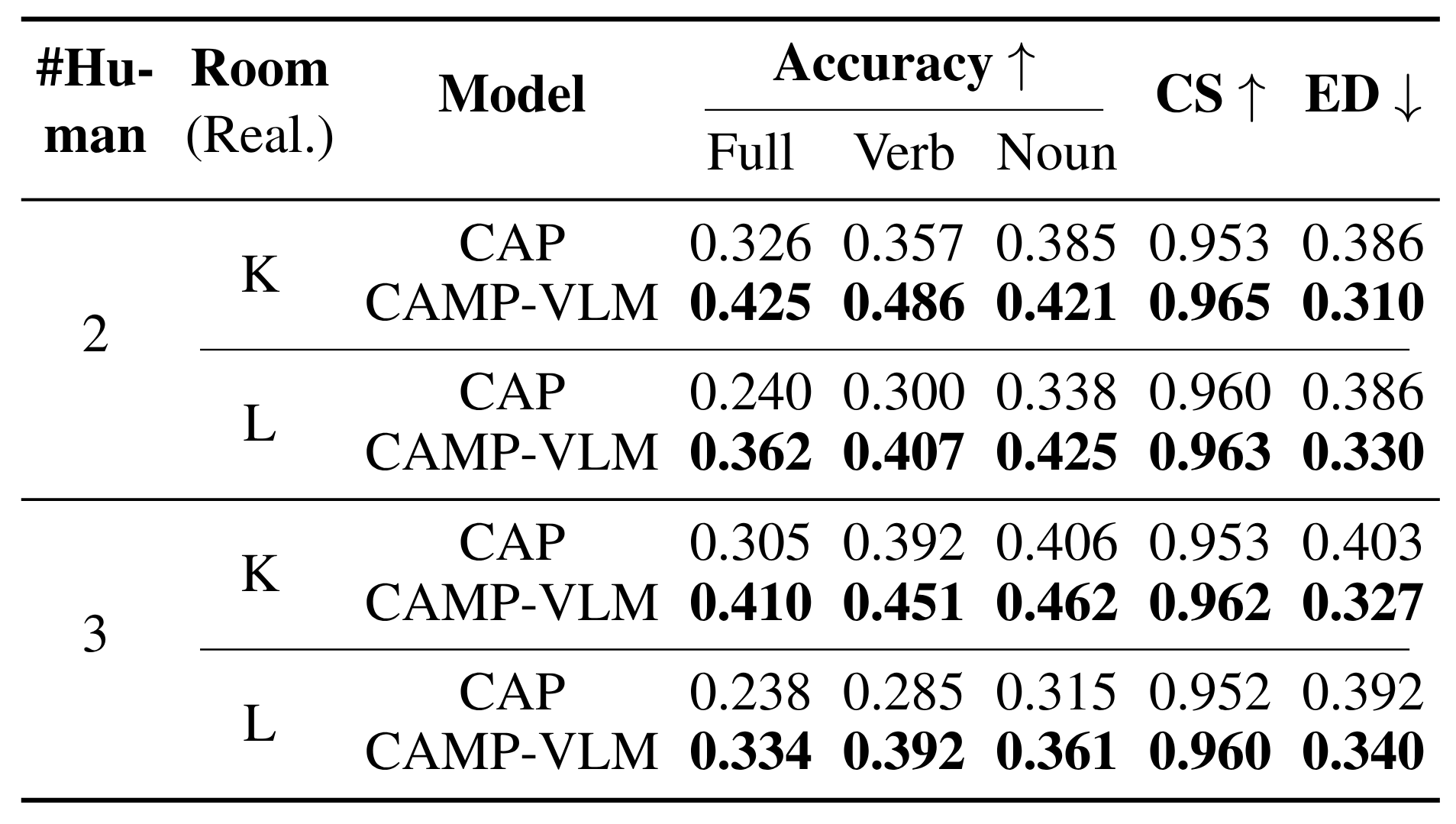
Results of CAMP-VLM and CAP in real-world multi-human scenarios in K(itchen) and L(iving room). Results of AntGPT are not listed due to low performance.
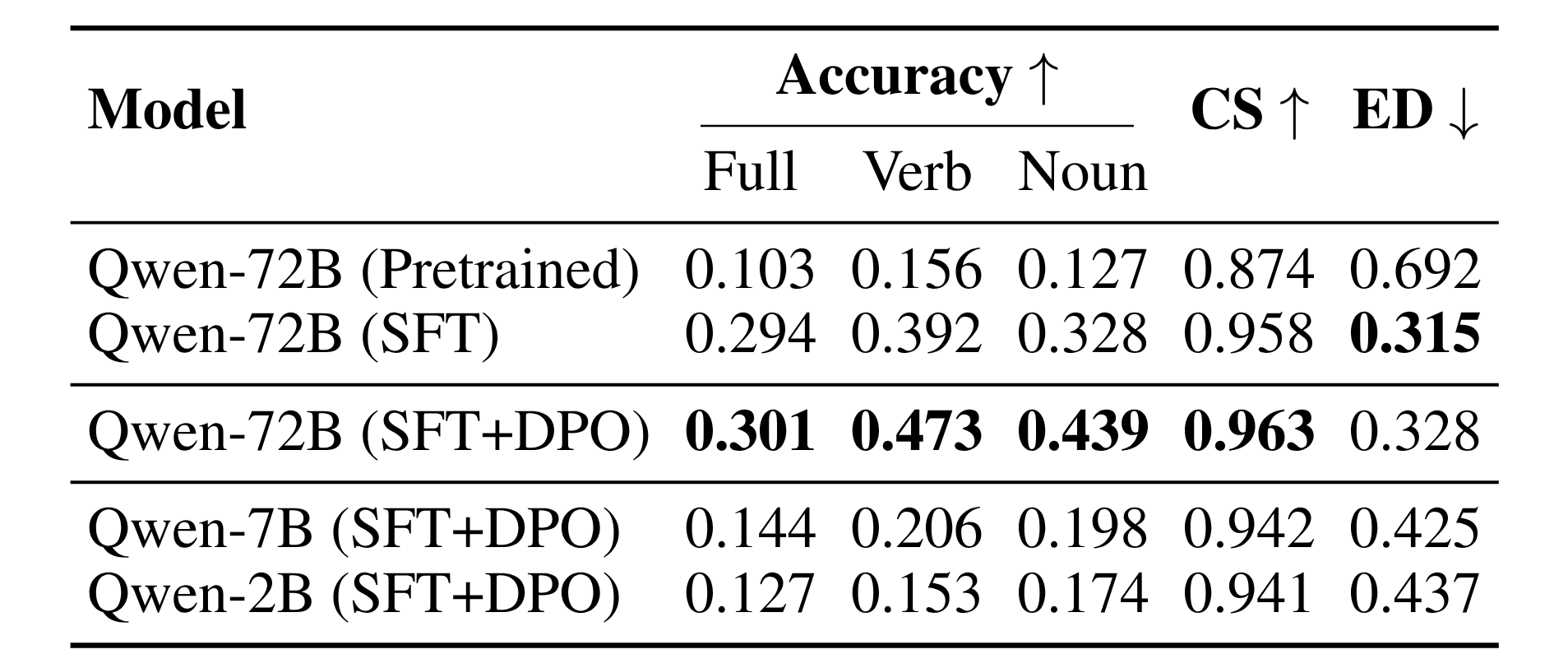
Performance of CAMP-VLM with different fine-tuning strategies and VLM variants in kitchen (syn.) with 3 humans.

Performance of CAMP-VLM with increasing number of humans. The values are averaged across all room types.
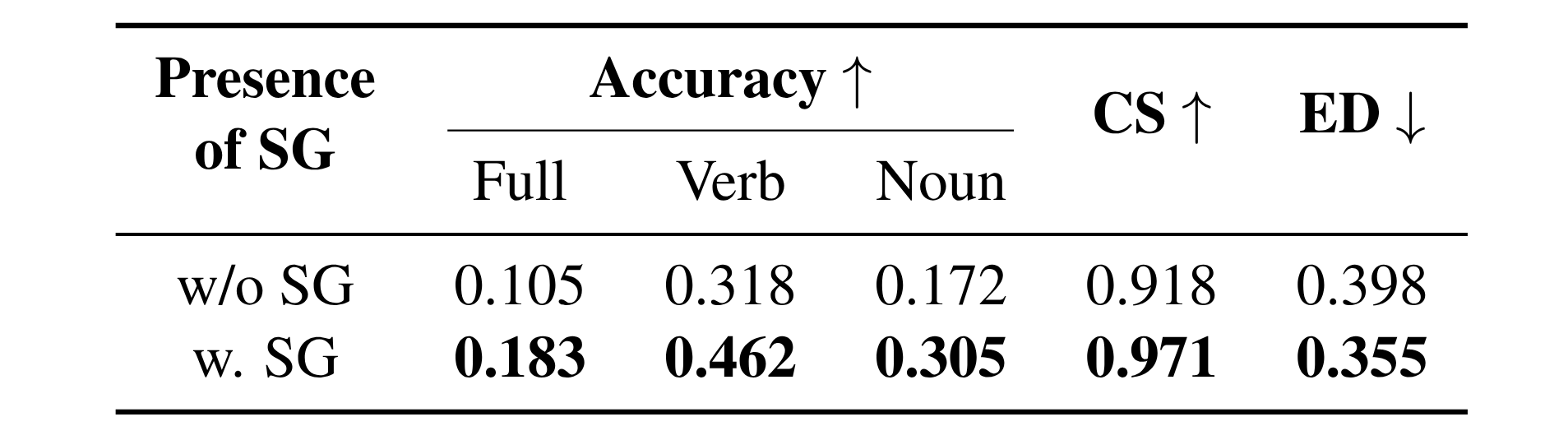
Comparison of performance with and without scene graphs using pretrained GPT-4o in kitchen (syn.) with 3 humans.
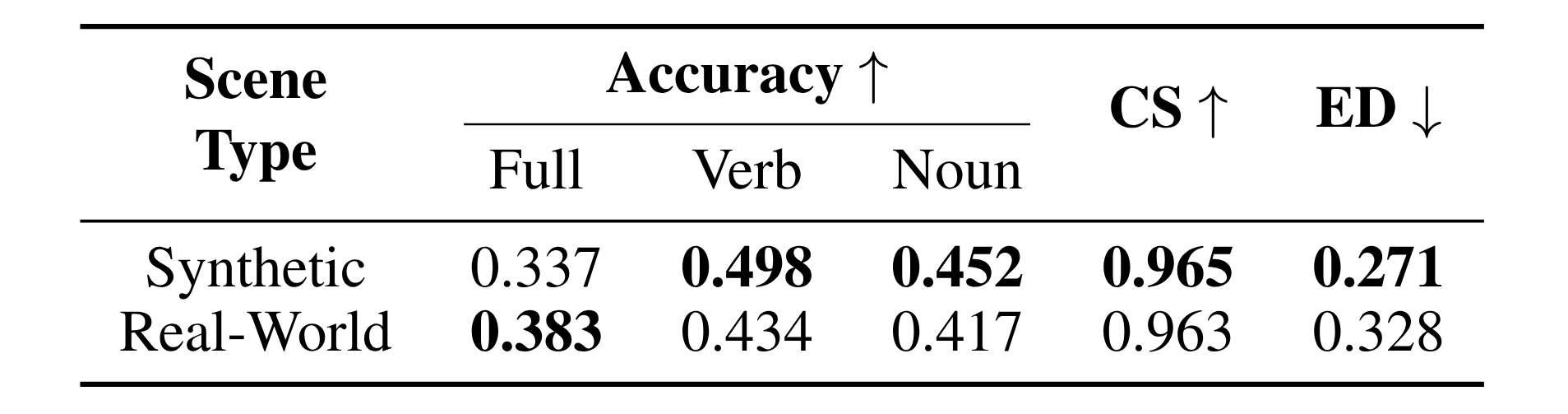
Comparison of prediction performance of CAMP-VLM between synthetic and real-world scenes. The values are averaged across all room types in 2 and 3 humans scenarios.
@article{panchal2025seeing,
title={Seeing is Believing (and Predicting): Context-Aware Multi-Human Behavior Prediction with Vision Language Models},
author={Panchal, Utsav and Liu, Yuchen and Palmieri, Luigi and Georgievski, Ilche and Aiello, Marco},
journal={arXiv preprint arXiv:2512.15957},
year={2025}
}